Penelitian kualitatif dan kuantitatif adalah dua pendekatan penelitian yang umum digunakan peneliti. Kedua pendekatan ini memiliki ciri khas masing-masing. Ciri tersebut meliputi metode penelitian, jenis dan sumber data, serta teknik analisa data. Tulisan ini hendak memaparkan hal-hal umum yang ada dalam konteks dua pendekatan penelitian ini.
Pendekatan Penelitian
Guna menjawab perumusan masalah penelitian yang sudah ditetapkan, peneliti memilih pendekatan penelitian. Pendekatan ini disesuaikan dengan kebutuhan pencarian jawaban atas pertanyaan penelitian (perumusan masalah).
Scott W. Vanderstoep and Deirdre D. Johnston menyatakan, kendati bervariasi, pendekatan penelitian dapat dikelompokkan ke dalam 2 bagian besar : Pendekatan Kualitatif dan Pendekatan Kuantitatif. Penelitian Kuantitatif menekankan pada penilaian numerik atas fenomena yang dipelajari. Pendekatan Kualitatif menekankan pada pembangunan naratif atau deskripsi tekstual atas fenomena yang diteliti. Ringkasan perbedaan kedua pendekatan penelitian ini adalah:

Metode Penelitian
Dalam ilmu sosial, kajian yang mengentara berlingkup pada penelitian perilaku (behavioral research). Sebagai “anak kandung” pendekatan Positivis, kajian behavioral berupaya melakukan kuantifikasi atas apapun, termasuk mengkuantifikasi data-data kualitatif menjadi data-data kuantitatif. Angka dan ketepatan pengukuran menjadi subyek utama dalam studi-studi perilaku.
Mark R. Leary membagi studi perilaku ke dalam 4 kategori besar yaitu : (1) Penelitian Deskriptif; (2) Penelitian Korelasional; (3) Penelitian Eksperimental; dan (4) Penelitian Kuasi-Eksperimental.
1. Penelitian Deskriptif
Penelitian Deskriptif menggambarkan perilaku, pemikiran, atau perasaan suatu kelompok atau individu. Contoh umum dari penelitian deskriptif adalah jajak pendapat, yang menggambarkan sikap suatu kelompok orang. Dalam Penelitian Deskriptif, peneliti kecil upayanya untuk menghubungkan perilaku yang diteliti dengan variabel lainnya ataupun menguji atau menjelaskan penyebab sistematisnya. Seperti namannya, Penelitian Deskriptif hanya mendeskripsikan.
Tujuan Penelitian Deskriptif adalah menggambarkan karakteristik atau perilaku suatu populasi dengan cara yang sistematis dan akurat. Biasanya, Penelitian Deskriptif tidak didesain untuk menguji Hipotesis, tetapi lebih pada upaya menyediakan informasi seputar karakter fisik, sosial, perilaku, ekonomi, atau psikologi dari sekelompok orang.
Jenis Penelitian Deskriptif yang biasa diterapkan adalah : (1) Penelitian Survey, (2) Penelitian Demografis, dan (3) Penelitian Epidemiologis.
2. Penelitian Korelasional
Penelitian Korelasional menyelidiki hubungan antara variabel-variabel psikologi yang beragam. Apakah ada hubungan antara Kepercayaan Diri dengan Rasa Minder? Apakah orang dewasa yang kecilnya diabaikan berhubungan dengan kenakalan di masa dewasa mereka? Penelitian Korelasional, singkatnya, mempertanyakan apakah ada correlation (hubungan) antara dua variabel.
Kala peneliti berminat dalam pertanyaan variabel-variabel apakah yang berhubungan satu sama lain, mereka melakukan Penelitian Korelasional. Penelitian Korelasional digunakan guna menggambarkan hubungan antara 2 atau lebih variabel-variabel yang muncul secara alamiah.
Dalam Penelitian Korelasional, terdapat Koefisien Korelasi. Koefisien Korelasi adalah suatu statistik yang mengindikasikan derajat mana dua variabel berhubungan satu sama lain dengan cara yang linier. Misalnya, hubungan antara kepribadian anak dengan kepribadian orang tua, konsumsi ganja dengan daya ingat, dan dengar musik rock n’ roll dengan niat merusak. Koefisien Korelasi berkisar dari -1 hingga 1. Jika Koefisien Korelasi berkisar dari > = -1 hingga < 0 maka korelasi negatif. Jika Koefisien Korelasi = 0 maka dianggap tidak ada korelasi. Jika Koefisien Korelasi > 0 dan < = 1 maka korelasi positif. Dalam Penelitian Korelasional juga terdapat Koefisien Determinasi. Koefisien Determinasi diperleh dari pengkuadratan nilai korelasi. Misalnya variabel kepribadian anak berhubungan dengan kepribadian orang tua dengan nilai r = 0.25. Koefisien Determinasi diperoleh dengan mengkalikan 0,25 x 0,25 = 0,0625. Nilai 0,0625 lalu dikalikan % sehingga menjadi 6,25%. Nilai 6,25% memberitahu peneliti bahwa 6,25% varians kepribadian anak juga terdapat dalam kepribadian orang tuanya. Perhitungan dalam Penelitian Korelasional kerap menggunakan Pearson Product Moment. Rumus Pearson Product Moment sebagai berikut:

Berdasarkan rumus tersebut, kita bisa menghitung Koefisien Korelasi dari data penelitian berikut ini :

Berdasarkan rumus Pearson Product Moment di atas, kita bisa melakukan perhitungan sebagai berikut:

Korelasi antara Test Score (x) dengan Job Performance Rating (y) adalah 0,82. Koefisien Determinasi-nya adalah 0,82 x 0,82 = 0,6724. Dengan demikian dapat dikatakan 67,24% varians Job Performance Rating dapat dihitung dengan mengetahui Test Score=nya. Test tersebut terlihat dapat dijadikan indikator valid bagi Job Performance.
Dalam Penelitian Korelasional juga terdapat istilah Statistical Significance. Statistical Significance hadir kala Koefisien Korelasi yang dihitung pada suatu sampel punya probability yang sangat rendah untu menjadi 0 dalam populasi. Hasil suatu uji statistik salah satunya bergantung pada jumlah sampel (responden). Besar nilai Koefisien Korelasi, bisa dikatakan signifikan atau tidak, salah satunya bergantung pada besar sampel ini. Perhatikan tabel di bawah ini:

Tabel di atas menggambarkan nilai minimal r yang dianggap Statistically Significant, dengan kurang dari 5% kesempatan bahwa korelasi dalam populasi menjadi 0. Misalnya, suatu Penelitian Korelasi menggunakan sampel sebesar 30 orang dan Koefisien Korelasi hitungnya sebesar 0,29. Penelitian Korelasional tersebut tidak Statistically Significant dalam probabilitas 0,05.
Penelitian Korelasional juga bisa diprospek lebih lanjut. Mark R. Leary sekurangnya menyebutkan 3 kembangan dari penelitian korelasional yaitu : (1) Analisis Regresi; (2) Cross-Lagged Panel dan Structural Equation Analysis; dan (3) Factor Analysis. Analisis Regresi bertujuan mengembangkan persamaan yang menggambarkan bagaimana variabel-variabel berhubungan dan memprediksi satu variabel oleh variabel lainnya. Cross-Lagged Panel dan Structural Equation Analysis bertugas menjelajahi arah kausalitas (sebab-akibat) antara dua atau lebih variabel yang berkorelasi (berhubungan). Faktor Analysis bertugas mengidentifikasi dimensi-dimensi dasar yang menggarisbawasi seperangkat korelasi.
3. Penelitian Eksperimental
Penelitian Eksperimental berminat menentukan apakah variabel-variabel tertentu menyebabkan perubahan perilaku, pemikiran, atau emosi. Dalam penelitian ini, peneliti memanipulasi atau mengubah satu variabel (disebut variabel bebas) guna melihat pakah perubahan dalam perilaku (varibel terikat) muncul sebagai akibatnya. Jika perubahan perilaku muncul kala variabel bebas dimanipulasi, maka peneliti dapat menyimpulkan bahwa variabel bebas menyebabkan perubahan pada variabel terikat (dalam kondisi tertentu).
4. Penelitian Kuasi-Eksperimental
Kala peneliti berminat memahami sebab dan akibat dari suatu hubungan, mereka memilih Penelitian Eksperimental. Namun, Penelitian Eksperimental mensyaratkan peneliti lincah mengubah-ubah variabel bebasnya guna menentukan efeknya atas variabel terikat. Dalam banyak kasus, peneliti tidak mampu mengubah variabel bebas. Kala ini terjadi, peneliti kadang menggunakan Penelitian Kuasi-Eksperimental. Dalam Penelitian Kuasi-Eksperimental, peneliti menyelidiki efek sejumlah variabel atau peristiwa secara alamiah.
Populasi
Populasi juga disebut populasi sasaran (target population), keseluruhan, atau sampling frame. Intinya, populasi adalah darimana sampel diambil. Populasi adalah agregat (pengelompokan) seluruh kasus yang disesuaikan dengan seperangkat kriteria yang ditentukan sebelumnya, misalnya variabel-variabel dan indikator-indikator penelitian yang ditetapkan peneliti.
Elemen-elemen populasi adalah anggota atau unit tertentu dari suatu populasi. Anggota atau unit populasi ini bisa berupa orang, tindakan sosial, peristiwa, tempat, waktu, atau masalah. Peneliti bebas menentukan populasi sesuai dengan perumusan masalah penelitian. Misalnya, sebuah populasi bisa dikatakan sebagai:
- Semua orang berusia 16 atau lebih tua yang tinggal di Wonosobo pada tanggal 2 Desember 1999, yang tidak pernah berurusan dengan hukum.
- Seluruh perusahaan yang memiliki lebih dari 100 karyawan di Provinsi Kepulauan Maluku dan beroperasi pada bulan Juli 2005.
- Seluruh mahasiswa STIA Sandikta yang lahir di Kota Bekasi mulai tahun 1975.
Target Population (populasi sasaran) mengacu pada kelompok spesifik yang peneliti ingin teliti. Perbandingan ukuran sampel dengan ukuran populasi disebut Sampling Ratio. Contoh, populasi punya 50.000 orang, dan peneliti memilih 150 sampel dari populasi tersebut. Sampling Ratio-nya 150/50.000 = 0,003 atau 0,3%. Jika populasi punya 500 orang dan peneliti mengambil sampel 100, lalu Sampling Ratio-nya 100/500 = 0,20 atau 20%.
Populasi adalah konsep yang abstrak. Sebab itu peneliti harus menaksir populasi. Sebagai konsep abstrak, populasi perlu dibuat definisi operasionalnya. Proses ini sama dengan membuat definisi operasional untuk konsep (variabel dan indikator) penelitian. Definisi operasional populasi telah kami sebutkan di bagian atas.
Definisi operasional populasi melahirkan Sampling Frame. Sampling Frame adalah daftar rinci yang taksirannya mendekati elemen-elemen dalam populasi. Gambaran Sampling Frame sebagai berikut:

Sampel dan Teknik Sampling
Sampel adalah sebagian populasi yang digunakan sebagai dasar penarikan kesimpulan penelitian. Peneliti menggunakan sampel sebagai cara utama guna menaksir perilaku di dalam suatu populasi. Sebab itu, patut dipertimbangkan secara serius pengambilan sampel ini.
Apa beda sensus dan sampel. Sensus adalah perhitungan seluruh elemen populasi dan digunakan untuk menggambarkan karakteristik populasi. Sampel adalah pemilihan elemen (anggota atau unit) dari suatu populasi; ia digunakan untuk membuat pernyataan yang mengatasnamakan populasi. Sampel ideal adalah sampel yang mewakili populasi secara sempurna, dengan seluruh ciri populasi termaktub di dalam sampel tersebut. Sampel ideal jarang terdapat dalam penelitian.
Probability Sampel memberi kesempatan kepada semua elemen populasi untuk menjadi sampel. Nonprobability Sample tidak memberi setiap anggota populasi kesempatan untuk dipilih. Hubungan antara ukuran sample dan ukuran populasi disebut dengan Sampling Ratio (rasio penyampelan).
Metode Sampling terdiri atas 2 bagian besar yaitu : (1) Probability Sampling, dan (2) Nonprobability Sampling. Probability Sampling kerap dikaitkan dengan penelitian Kuantitatif. Nonprobability Sampling kerap dikaitkan dengan penelitian Kualitatif. Namun, penelitian kuantitatif yang kini beredar banyak pula yang menggunakan Nonprobability Sampling untuk menentukan unit analisisnya.
1. Sampel Saya Harus Berapa?
Tidak ada jumlah akurat berapa sampel harus dipakai. Semua bergantung pada tujuan dan metode penelitian yang digunakan peneliti. Namun, sekadar acuan belaka penentuan jumlah sampel, Cohen dan rekan-rekannya memberikan secara jelas dan mudah dipahami.
Misalnya, Penelitian Korelasional butuh sampel minimal 30 responden. Penelitian Eksperimental, Kausal-Komparatif, butuh minimal 15 responden/obyek. Penelitian Survey (masuk kategori Penelitian Deskriptif) butuh minimal 100 responden kelompok utama dan minimal 50 responden kelompok minor. Penelitian Lapangan atau Etnografis (kualitatif) tentunya butuh sampel tidak sebesar penelitian kuantitatif karena tingkat kesulitannya. Penentuan jumlah sampel juga dibatasi masalah biaya, waktu, uang, stress, dukungan administratir, jumlah penelitian dan sumberdaya.
Dalam konteks Sample Acak (Random Sampling), sampel dapat ditentukan dengan dua cara. Entah itu peneliti dengan cara pertimbangan jujur peneliti bahwa sampel mewakili populasi dengan menetapkan jumlah sampel minimal. Atau, dengan menggunakan tabel yang dibuat dengan rumus matematika yang menghasilkan jumlah sampel yang mencukupi bagi jumlalh populasi tertentu. Contoh sampel dengan cara ini adalah yang dikembangkan Krejcie and Morgan tahun 1970 yang populer dengan nama Tabel Krejcie and Morgan, yang tabelnya sebagai berikut :
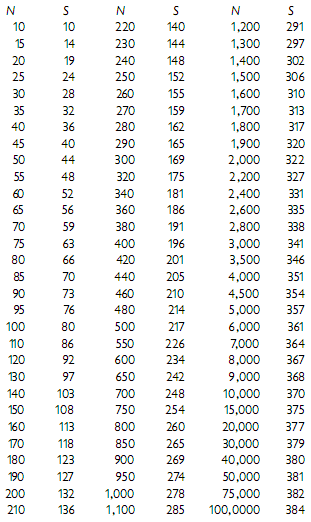
Dimana :
- N = Populasi
- S = Sampel
Dari tabel Krejcie and Morgan di atas, kentara bahwa semakin kecil jumlah populasi, semakin besar sampel yang harus diambil dari populasi tersebut. Semakin besar jumlah populasi, semakin kecil jumlah sampel yang harus diambil dari populasi tersebut. Tabel Krejcie and Morgan sangat populer digunakan guna menentukan jumlah sampel yang kesederhanaannya.
Cara lain untuk menentukan besar sampel adalah dengan memperhitungkan Taraf Keyakinan dan Sampling Error penelitian. Misalnya, dengan Taraf Keyakinan 95% dan 99% dan Sampling Error 5% dan 1%, jumlah sampel baru ditentukan. Cohen dan rekan-rekannya lalu membentuk tabel penentuan jumlah sampel berdasarkan Taraf Keyakinan dan Sampling Error penelitian sebagai berikut:
 |
| Menentukan sampel |
Tabel Cohen dan rekan-rekan di atas terdiri atas 3 Taraf Keyakinan penelitian yaitu (kiri ke kanan) 90%, 95%, dan 99%. Di masing-masing Taraf Keyakinan, Cohen dan rekan-rekan juga memuat 3 Interval Keyakinan yaitu (kiri ke kanan) 5%, 4%, dan 3%. Misalnyanya Boim membuat penelitian yang Populasi-nya 1.000.000 orang dengan Taraf Keyakinan Penelitian 95% dan Interval Keyakinan 3%, maka Sampel Boim harus 1.066 orang. Mudah sekali, bukan?
Cara lain menentukan jumlah sampel adalah dengan menggunakan rumus Slovin. Rumus Slovin adalah:

Dimana:
- n = Sampel
- N = Populasi
- e = Interval Keyakinan (biasanya 0,05 atau 0,01).
Misalnya Boim mengadakan penelitian dengan populasi 1000 orang. Interval Keyakinan penelitian yang dipakai 0,05. Maka perhitungan sampel Boim :

Dengan demikian, Boim harus menggunakan sampel sebesar 286 orang.
2. Probability Sampling
Probability Sampling terdiri atas: (1) Simple Random Sampling; (2) Systematic Sampling; (3) Stratified Sampling; dan (4) Cluster Sampling. Pembahasan masing-masingnya ada di bagian bawah berikut.
Simple Random Sampling. Simple Random Sampling adalah sampel acak yang paling mudah dipahami dan paling banyak dimodelkan. Dalam Simple Random Sampling, penelitia mengembangkan Sampling Frame yang akurat, memilih elemen-elemen dari Sampling Frame menurut prosedur acak matematika, lalu memilih siapa atau apa yang dijadikan sampel.
Dalam Simple Random Sampling, setiap unit di dalam populasi punya kesempatan untuk dipilih sebagai sampel penelitian. Penelitian mulai dengan daftar observasi yaitu N. N adalah seluruh populasi yang ditentukan dalam Sampling Frame.
Contoh, dalam wilayah pemungutan suara terdapat 1000 pemilih. Peneliti hendak memilih 100 dari antara mereka untuk jajak pendapat. Peneliti memasukkan ke-1000 nama di sebuah kotak dan mengeluarkan 100 nama. Dengan ini, 1000 orang tersebut punya kesempatan yang sama untuk menjadi sampel. Peneliti menentukan ukuran n (sampel) dan N (populasi) dan masukkan ke dalam pembagian :
n/N x 100 atau 100/1000 x 100 = 10%.
Dengan demikian, sampel yang digunakan adalah 10% dari populasi. Syarat utama Simple Random Sampling adalah membuat Sampling Frame. Sampel diturunkan dari Sampling Frame ini.
Dalam memilih sampel dengan teknik Simple Random Sampling digunakan Tabel Random Number (nomor acak) yang kami muat dalam lampiran tulisan ini. Bagaimana cara menggunakannya? Cara menggunakan sebagai berikut:

Perhatikan, tabel terdiri atas dua digit angka (54, 83, 80, ...).
- Angka-angka tersebut disusun dalam bentuk baris dan kolom agar mudah dibaca dan digunakan.
- Pada prakteknya, anda abaikan 2 digit itu dan khayalkan angka-angka tersebut berbentuk sambung (5, 4, 8, 3, 8, 0, 5, 3, 9, 0, ...).
- Tentukan berapa sampel yang mau diambil. Misalnya, STIA Sandikta punya 5000 mahasiswa dan Peneliti mau mengambil sampel 200 sampel.
- Buatlah nomor (di kertas coret-coretan) mahasiswa nomor 0001 hingga 5000.
- Mulai dari mana saja, pada tabel Random Number, peneliti mau ambil 200 set 4 digit angka.
Contoh, peneliti mulai dari sini (cetak tebal):
36 85 49 83 47 89 46 28 54 02 87 98 10 47 22 67 27 33 13
- Mulai dari nomor 49 itu lihat ke samping kanan sehingga jadi 4983. Mahasiswa nomor 4983 jadi sampel. Baru satu orang. Di samping kanannya 4789. Ia jadi sampel nomor 2. Ke samping kanannya lagi 4628. Ia jadi sampel nomor 3. Ke samping kanan lagi ketemu 5402. Lho!
- Mahasiswa kan Cuma 5000 sehingga 5402 tidak ada. Jangan hiraukan, dan lanjut ke kanan lagi ketemu 8798. Abaikan juga nomor tersebut. Ke kanan lagi ketemu 1047. Nah, 1047 ini jadi sampel nomor 4. Begitu selanjutnya dan selanjutnya hingga ketemu 200 sampel.
Stratified Random Sampling. Stratified Random Sampling adalah variasi dari Simple Random Sampling. Ketimbang memilih responden langsung dari populasi, peneliti pertama-tama membagi populasi ke dalam 2 atau lebih strata. Stratum adalah bagian dari populasi yang saling berbagi karakteristik khusus tertentu.
Contoh, peneliti bisa membagi populasi jadi Laki-laki dan Prempuan atau ke dalam 6 kisaran umur (20-29, 30-39, 40-49, 50-59, 60-69, di atas 69). Lalu, responden ditarik acak dari tiap-tiap strata.
Kunci Stratified Random Sampling adalah, peneliti punya informasi tambahan seputar stratum yang ada dalam populasi. Di atas sudah dicontohkan jenis kelamin dan kisaran umur. Juga bisa berupa jabatan seperti bos, wakil bos, anak buah bos, dan sejenisnya. Sampel lalu diambil dari tiap-tiap stratum tersebut.
Stratified Random Sampling mengatasi kelemahan Simple Random Sampling. Misalnya, suatu populasi terdiri atas 100 orang. Terdapat 60% laki-laki dan 40% prempuan. Rasio laki-laki dan prempuan 60:40. Kalau pakai Simple Random Sampling, rasio tersebut belum tentu terpenuhi. Kalau pakai Stratified Random Sampling, maka sampel yang ditarik mencerminkan rasio tersebut dengan cara:
- (10/100) x 60 = 6 laki
- (10/100) x 40 = 4 prempuan
Contoh dari Stratified Random Sampling dan perbandingannya dengan Simple Random Sampling sebagai berikut:

Dalam tabel di atas, pilih 3 dari 15 administrator, 5 dari 25 Staff Physician, dan selanjutnya. Secara umum, N menyimbolkan angka dalam populasi dan n mewakili angka dalam sampel. Simple Random Sampel berlebihan dalam mengambil Nurses, Nursing Assistant, dan Medical Technician, tetapi kurang dalam mewakili Administrator, Staff Physician, Maintenance Staff, dan Cleaning Staff. Namun, Stratified Random Sampling memberi perwakilan lebih akuran untuk tiap jenis posisi. Kiranya demikian dan cukup sederhana, bukan?
Cluster Sampling. Cluster Sampling dipilih sebagai metode penarikan sampel jika terdapat dua masalah. Pertama, tidak punya Sampling Frame yang baik bagi populasi yang tersebar. Kedua, biaya untuk mengambil sampel tinggi (mahal, expensive).
Contoh, tidak terdapat daftar nama montir di wilayah Kota Bekasi. Bahkan, jika peneliti punya Sampling Frame yang akurat, proses penyebaran kuesioner memakan biaya mahal karena para montir tersebar di kawasan yang luas dan macet serta berpolusi. Resiko kesehatan jiwa pun mengancam. Jadi, ketimbang memakai satu Sampling Frame, peneliti mengguna desain sampel yang meliputi Multiple Stages dan Cluster.
Cluster adalah pengelompokan responden. Dalam kasus montir di Kota Bekasi, para montir kelompokkan. Pengelompokkan biasanya berdasarkan wilayah geografis. Dalam kasus montir di Kota Bekasi, peneliti melakukan hal-hal berikut dalam metode Cluster Sampling:
- Tujuan : Memilih 240 orang montir di Kota Bekasi.
- Langkah#1 - Kota Bekasi punya 12 kecamatan dan 56 kelurahan. Peneliti tentukan hendak mengambil montir berdasarkan apa ? Kecamatan atau kelurahan? Disarankan kelurahan saja karena lingkupnya lebih sempit. Dari 56 kelurahan, pilih secara acak 6 kelurahan. [yang ditebalkan dipilih secara acak, lho!]

- Langkah#2 - Bagilah kelurahan yang sudah dipilih ke dalam RW. Tiap kelurahan terdiri dari 20 RW. Lalu pilih secara acak 5 RW dari tiap kelurahan.
- Contoh kelurahan 03 adalah Jatirahayu (sudah dipilih di langkah 1) yang punya 20 RW: maka seperti ini:
01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 17 18 19 20
- Dipilihlah RW 04, 10, 13, 17, dan 20.
- Langkah#3 - Dari tiap RW cari 10 montir buat mengisi kuesioner. Jadi, dari kelurahan Jatirahayu dapat 40 montir. Lakukan berulang langkah 2 dan 3 hingga total montir yang diperoleh adalah 240. Mudah bukan?
Tentu saja, Cluster Sample akurasinya lebih rendah ketimbang Simple Random Sampling. Namun, Cluster Sampling lebih murah biaya dan sederhana.
Systematic Sampling. Systematic Sampling adalah Simple Random Sampling dengan jalan pintas menuju pilihan acak. Langkah pertama menomori tiap elemen di dalam Sampling Frame. Lalu, ketimbang langsung menggunakan Tabel Random Number, peneliti menghitung Sampling Interval, dan interval itu menjadi metode semi acak dari si peneliti. Sampling Interval (misalnya 1 dalam k, di mana k ada suatu angka) memberitahu peneliti bagaimana memilih elemen dari Sampling Frame dengan cara melewati elemen di dalam Sampling Frame sebelum memilihnya jadi sampel.
Misalnya, peneliti STIA Sandikta mau pililh 300 nama dari 900 nama. Setelah awal yang acak, peneliti tersebut memilih tiap 3 nama dari 900 itu biar bisa beroleh 300 nama. Sampling Interval-nya, dengan demikian, adalah 3.
Sampling Interval mudah dihitung. Peneliti STIA Sandikta itu Cuma butuh jumlah sampel dan jumlah populasi (atau Sampling Frame). Sampling Ratio untuk 300 nama dari 900 adalah 300/900 = 0,333 = 33,3%. Sampling Interval adalah 900/300 = 3.
Contoh lain lagi soal Systematic Sampling. Mahasiswa STIA Sandikta ada 500 orang dan Boim, seorang peneliti, hendak mengambil sampel (n) sebanyak 100 menggunakan Systematic Sampling. Boim harus mendaftar ke-500 mahasiswa secara urut. Sampling Fraction-nya menjadi f = 500/100 = 20%. Dalam kasus Boim, ukuran Interval k sama dengan N/n = 500/100 = 5. Sekarang, Boim tinggal memilih integer (bilangan) acak dari 1 hingga 5. Taruhlah Boim memilih 2. Lalu, untuk memilih sampel Boim mulai dengan nomor 2 dan mengambil tiap k (yaitu 5, karena k = 5). Sampel Boim yaitu jatuh pada nomor 2, 7, 12, 17 dan terus begitu hingga anggota populasi nomor 500. Jadilah Boim beroleh 100 orang.
3. Non Probability Sampling
Non Probability Sampling terdiri atas: (1) Convenience Sampling; (2) Quota Sampling; (3) Purposive Sampling; (4) Snowball Sampling; (5) Deviant Case Sampling; dan (6) Sequential Sampling. Kendati lebih banyak digunakan dalam penelitian kualitatif, pada kenyataannya, banyak juga penelitian kuantitatif yang menggunakan metode sampling ini. Alasannya, banyak berkisar pada “kemalasan” peneliti, keterbatasan dana, keterbatasan waktu studi, dan alasan lebih praktis dan kemudahan penentuan.
Convenience Sampling. Convenience Sampling disebut juga Haphazard atau Accidental Sampling. Convenience Sampling sebagai metode sampling bisa berakibat pada sampel yang tidak efektif (tidak menggambarkan populasi) dan tidak direkomendasikan.
Convenience Sampling adalah sampel yang dipilih secara convenience (nyaman) karena sifatnya yang mudah dan tidak menyulitkan peneliti. Contoh dari Convenience Sampling adalah sebuah surat kabar bertanya pada pembaca lewat kolom kuesioner di surat kabar tersebut. Tidak semua orang yang baca koran punya minat pada masalah di dalam kuesioner, atau punya waktu buat menggunting kuesioner dan mengirimkannya lewat pos kendati gratis.
Andai saja ada 5000 orang yang mengembalikan, tetapi kendati besar “sampel” itu tidak bisa secara akurat menggambarkan populasi. Mungkin saja, kuesioner tersebut lebih punya nuansa menghibur ketimbang melakukan penelitian. Hasil kesimpulan penelitian seperti ini mendistorsi kesimpulan atas topik di dalam kuesioner.
Quota Sampling. Quota Sampling adalah upaya memperbaiki kelemahan Convenience Sampling. Dalam Quota Sampling, peneliti awalnya mengidentifikasi kategori-kategori yang relevan dari sejumlah orang (misalnya laki – prempuan atau < 30 tahun, 30 – 60 tahun, > 60 tahun), lalu memutuskan seberapa banyak dibutuhkan dari setiap kategori untuk dijadikan sampel. Sebab itu, jumlah orang di kategori sampel yang beragam itu fix.
Misalnya, peneliti memutuskan memilih 5 laki dan 5 prempuan di bawah umur 30 tahu, 10 laki dan 10 prempuan antara 30 – 60 tahun, dan 5 laki dan 5 prempuan di atas umur 60 tahun dalam menentukan 40 sampel yang dikehendaki. Adalah sulit mewakili seluruh karakteristik populasi secara akurat.
Quota Sampling adalah “perbaikan” Convenience Sampling karena peneliti dapat memastikan sejumlah perbedaan di dalam sampel-nya. Dalam Convenience Sampling, orang yang diwawancara atau mengisi kuesioner bisa saja berasal dari usia atau jenis kelamin yang serupa. Namun, Quota Sampling mengatasi kelemahan itu dengan menentukan variasi di dalam populasi. Quota Sampling ini kerap dilakukan Gallup’s American Institute of Public Opinion dalam memprediksi Presiden Amerika Serikat. Mereka sukses dalam pilpres 1936, 1940, dan 1944, tetapi tahun 1948 mereka salah memprediksi.
Purposive Sampling. Purposive Sampling juga disebut Judgmental Sampling. Purposive Sampling digunakan dalam situasi dimana seorang ahli menggunakan penilaiannya dalam memilih responden dengan tujuan tertentu di dalam benaknya. Dengan Purposive Sampling, peneliti tidak pernah tahu apakah responden yang dipilih mewakili populasi. Metode ini kerap digunakan dalam Exploratory Research atau dalam Field Research.
Purposive Sampling signifikan digunakan dalam 3 situasi. Pertama, peneliti menggunakan guna memilih responden unik yang akan memberi informasi penting. Contoh, peneliti ingin menggunakan Content Analysis guna meneliti Majalah untuk menemukan tema-tema kebudayaan. Ia memilih majalah prempuan populer untuk penelitian karena trend-nya membicara budaya.
Kedua, peneliti menggunakan Purposive Sampling untuk memilih responden yang sulit dicapai, yaitu suatu populasi khusus semisal kaum Gay atau Lesbian. Misalnya, peneliti hendak meneliti masalah prostitusi. Mustahil peneliti mendaftar seluruh nama pelacur di suatu lokalisasi dan secara acak memilih lewat teknik Simple Random Sampling. Untuk itu, peneliti cenderung informasi subyektif (misalnya lokalisasi pelacuran atau dengan siapa pelacur biasa berhubungan) dan para ahli (polisi susila, satpol PP, atau LSM pemerhati pelacur) guna mengidentifikasi sampel para pelacur untuk digunakan dalam penelitian.
Ketiga, tatkala peneliti ingin mengidentifikasi jenis responden tertentu untuk diadakan wawancara mendalam. Tujuan penelitian bukan hendak melakukan generalisasi atas populasi yang lebih besar, tetapi lebih pada kehendak untuk memperoleh informasi yang mendalam tentang sesuatu hal. Misalnya, Boim menggunakan Purposive Sampling dalam Focus Group Study seputar apa yang dipikirkan kelas pekerja tentang politik. Boim menghendaki 188 orang dari kelas pekerja untuk berpartisipasi dalam 1 dari 37 Focus Group yang dibentuk. Ia mencari responden yang tidak merampungkan pendidikan tinggi tetapi bervariasi dari segi usia, etnis, agama, minat politik dan jenis pekerjaan. Boim merekrut orang dari 35 kawasan di Kota Bekasi.
Snowball Sampling. Snowball Sampling juga disebut Network Sampling, Chain Referral Sampling atau Reputational Sampling. Snowball Sampling adalah metode guna mengidentifikasi dan mengambil sampel lewat suatu jaringan. Ia didasarkan pada analogi bola salju, yang dimulai dalam ukuran kecil, tetapi seiring proses, jumlahnya membesar. Snowball Sampling adalah teknik multi tahap. Ia dimual dengan sedikit orang dan membesar sehubungan pergerakan peneletian.
Snowball Sampling dapat dilakukan dengan membuat sosiogram, yaitu suatu diagram lingkaran yang dihubungkan dengan garis. Misalnya Boim dan Ratna tidak kenal satu sama lain secara langsung, tetapi tiap mereka punya teman yaitu Eka sehingga Boim dan Ratna berteman secara tidak langsung. Snowball Sampling kerap digunakan bersamaan dengan Purposive Sampling.
Deviant Case Sampling. Deviant Case Sampling juga disebut Extreme Case Sampling. Deviant Case Sampling digunakan kala peneliti mencari responden yang berbeda dari pola-pola dominan yang berkembang. Sama dengan Purposive Sampling, Deviant Case Sampling digunakan saat peneliti menggunakan teknik yang beragam untuk menempatkan responden dengan karakteristik tertentu. Deviant Case Sampling beda dengan Purposive Sampling karena tujuannya mencari hal yang unik, khusus, tidak biasa, bukan mewakili seluruhnya.
Misalnya, Boim tertarik meneliti mahasiswa STIA Sandikta yang dropout. Riset-riset sebelumnya menyebut mahasiswa tersebut dropout berasal dari keluarga yang punya pendapatan rendah, orang tua bercerai atau tidak stabil, sering pindah rumah, dan secara etnis atau agama minoritas. Penelitian yang sudah dibuat juga menyebut mahasiswa yang dropout kerap terlibat dalam perilaku ilegal dan punya catatan kriminal. Berdasarkan ini, Boim lalu menyusun penelitian dengan metode Deviant Case Sampling, di mana ia menggunakan responden mahasiswa STIA Sandikta yang dropout, tetapi tidak punya catatan kriminal, berasal dari etnis dan agama dominan, tidak pernah berperilaku ilegal apalagi melanggar hukum, dan secara ekonomi sangat mampu.
Sequential Sampling. Sequential Sampling mirip dengan Purposive Sampling dengan satu perbedaa. Dalam Purposive Sampling, peneliti coba menemukan sebanyak mungkin responden yang relevan dengan masalah penelitian, hingga suatu saat uang, tenaga, dan jiwa peneliti mulai “menjerit.”
Dalam Sequential Sampling, peneliti terus mengumpulkan responden hingga jumlah informasi baru atau keragaman responden yang baru terpenuhi. Contoh, Boim menentukan dan merencanakan wawancara mendalam dengan 60 janda di atas umur 70 tahun yang telah hidup tanpa pasangan selama sekurangnya 10 tahun. Bergantung pada tujuan Boim, memperoleh tambahan 20 janda yang pengalaman hidup, latar belakan sosial, dan pandangan hidup berbeda kecil dari 60 orang tersebut bisa dibilang tidak dibutuhkan.
4. Standard Error (SE)
Dalam proses pengambilan sampel (sampling method) dikenal istilah Standard Error. Standard Error ini berbeda dengan Standard Deviation (SD). SD mengukur seberapa baik Mean mewakili data. Semakin kecil SD mengindikasikan data dekat dengan Mean. Semakin besar SD mengindikasikan data jauh dari Mean. Jika SD = 0 maka Mean seluruh data adalah serupa. SD dapat dicari dengan rumus:

Dimana :
- s = Standar Deviasi
- x_i = Mean data yang diobservasi
- x ̅ = Mean data keseluruhan
- N = Jumlah sampel
Telah dikatakan, SD adalah akar kuadrat dari Varians (s2). Rumus Varians adalah :

Dimana :
- SS = Sum of Square Error
- N = Sampel
- x_i = Mean data yang diobservasi
- x ̅ = Mean data keseluruhan
- N = Jumlah sampel
Standard Error adalah seberapa baik sampel mewakili populasi. Standard Error berkaitan dengan sampel ini juga disebut Standard Error of the Mean (SE). SE menunjukkan seberapa jauh perbedaan Mean sampel dengan Mean populasi. SE dihitung dengan membagi SD sampel (s) dengan akar kuadrat total sampel (N):

Dimana :
- σx = Standard Error
- s = Standard Deviasi
- N = Jumlah sampel
5. Tingkat Keyakinan (Confidence of Interval)
Tingkat Keyakinan atau Confidence of Interval masih berkait dengan mean populasi. Tingkat Keyakinan adalah pendekatan untuk menilai akurasi Mean Sampel dalam menaksir Mean Populasi. Caranya dengan menghitung batas-batas dalam mana peneliti yakin nilai Mean Populasi yang sesungguhnya berada. Batas-batas ini disebut Tingkat Keyakinan. Gagasan dasar Tingkat Keyakinan adalah menaksir kisaran nilai ke dalam mana peneliti pikir nilai Mean populasi berada. Tingkat Keyakinan yang populer dalam penelitian sosial adalah 90%, 95% atau bahkan 99%.
Misalnya, suatu penelitian menggunakan 95% Tingkat Keyakinan dan menggunakan 100 sampel. Kita meneliti 100 sampel, menghitung Mean sampel, dan menghitung Tingkat Keyakinan untuk mean tersebut, lalu untuk 95 dari 100 sampel tersebut, Tingkat Keyakinan yang kita bangun akan mengandung nilai sesungguhnya dari Mean Populasi. Atau, jika Tingkat Keyakinan yang digunakan 90%, maka hanya 90 sampel saja yang mengandung nilai sesungguhnya dari Mean Populasi.
Untuk menghitung Tingkat Keyakinan, kita perlu tahu batas-batas dalam mana 95% Mean akan jatuh. Untuk itu perlu kita ingat z-score sebagai distribusi normal data. Nilai z-score diperoleh dari:

Dimana :
- z = z-score
- X = Standard Deviasi
- X ̅ = Mean Sampel
- s = Standard Error
Batasan kiri –1,96 dan kanan 1,96. Untuk itu, kita mengganti z pada persamaan dengan :

Nilai X diperoleh dari :

Dengan demikian, batas bawah dari Tingkat Keyakinan adalah:

Dan, batas atas dari Tingkat Keyakinan adalah:

Tingkat Keyakinan yang digunakan dalam penelitian ini adalah 95% dan dengan demikian signifikansi hasil uji statistik yang dikehendaki adalah < 0,05. Uji statistik yang digunakan menggunakan Uji Dua Sisi karena nilai gap yang diperoleh belum bisa dipastikan bernilai negatif (-) atau positif (+). Nilai z-score untuk signifikansi 0,05 untuk uji dua sisi telah distandardisasi, dan nilainya adalah – 1,96 untuk batas bawah dan 1,96 untuk batas atas.
Jenis dan Sumber Data
Jenis data primer yang dibutuhkan penelitian ini adalah data kualitatif berupa sikap pelanggan suatu perusahaan. Data berupa sikap tersebut dikuantifikasi dengan menggunakan skala ordinal. Kendati telah dikuantifikasi, data yang dihasilkan tetaplah data kualitatif.
Data kualitatif tersebut, lebih lanjut dikuantifikasi kembali dengan mengkategosasinya berdasarkan variabel X dan variabel Y. Variabel X terdiri atas .... dengan indikator-indikator .... Sementara variabel Y terdiri atas ..... dengan indikator-indikator .....
Selain data primer yang diperoleh berdasarkan penyebaran kuesioner, data primer juga diperoleh melalui wawancara terbuka kepada para responden. Data sekunder diperoleh dengan studi dokumentasi dan perpustakaan.
Teknik Pengukuran
Variabel X dan Variabel Y serta indikator-indikator yang ada di dalam Hipotesis penelitian harus diukur. Pengukuran ini ditentukan oleh sifat data, yaitu apakah Diskrit atau Kontinus. Selain itu, teknik pengukuran juga pada instrumen pengukurannya (skala).
1. Sifat Data
Pertama-tama peneliti harus menetapkan skala pengukuran yang digunakan untuk mengukur konsep. Skala pengukuran dari terendah hingga tertinggi adalah: (1) Nominal; (2) Ordinal; (3) Interval, dan (4) Rasio. Skala pengukuran membatasi uji-uji statistik yang diterapkan dalam analisis data.
Nominal adalah skala yang hanya mengukur perbedaan antar kategori. Misalnya agama yaitu Protestan, Katolik, Islam, Yahudi, Buddha. Atau, ras seperti Afro-Amerika, Kaukasus, Hispanik, Arian, atau Mongoloid. Ordinal adalah skala yang hanya mengukur perbedaan ditambah kategori yang bisa diurutkan atau dirangking seperti Tinggi, Rendah, Sedang atau sikap (Sangat Setuju, Setuju, Tidak Setuju, Sangat Tidak Setuju).
Interval mengukur apa yang bisa diukur nominal dan ordinal ditambah skala ini bisa merinci jarak antar kategori seperti Skor IQ (95, 110, 125) atau temperatur (5 derajat, 7, derajat, atau 9 derajat). Rasio bisa mengukur apa yang bisa diukur nominal, ordinal, dan rasio ditambah rasio punya titik 0 yang pasti seperti uang (1 rupiah, 2 rupiah) atau tahun belajar (1 tahun, 2 tahun, 3 tahun).
Khusus mengenai skala sikap, peneliti berbeda pendapat apakah memasukkan peringkat sikap ke dalam skala ordinal atau interval. Donald P. Schwab menyatakan keraguan ini. Di tengah keraguan ini, Schwab menyatakan bahwa peringkat sikap jika tidak bisa dikatakan berskala Interval sekurangnya adalah “mendekati” Interval. Schwab juga berani menyatakan bahwa, dengan “mendekati” Interval, uji-uji statistik yang biasa digunakan untuk skala Interval bisa dilakukan atas skala sikap yang “mendekati” Interval ini.
2. Skala Pengukuran
Skala alat ukur (dalam kuesioner sikap) yang biasa digunakan adalah Likert, Bogardus Social Distance Scale, Semantic Differential, dan Guttman Scaling.
Skala Likert. Skala Likert diciptakan tahun 1930 oleh Rensis Likert guna menyediakan tingkat Ordinal bagi pengukuran sikap seseorang. Likert menggunakan pilihan Setuju atau Tidak Setuju atas suatu pernyataan. Skala Likert minimal terdiri atas 2 pilihan jawaban (kategori). Lebih baik lagi jika mau menggunakan 4 hingga 8 pilihan jawaban.
Contoh-contoh Skala Likert kami sampaikan di bawah ini :
Skala Self-Esteem Rosenberg. Contoh dari skala yang menggunakan Rosenberg ini adalah:
Di atas semuanya, saya leluasa menyatakan bahwa saya keliru:
- Hampir selalu.
- Seringkali.
- Kadang.
- Jarang.
- Tidak Pernah.
Misalnya, diterapkan pada kasus Skala Penilaian Pengajaran oleh Mahasiswa:
Secara keseluruhan, saya memberi peringkat atas pengajaran di mata kuliah ini sebagai:

Atau, misalnya diterapkan pada Skala Supervisor Kelompok Kerja
Supervisor saya:

Bogardus Social Dimension Scale. Bogardus Social Dimension Scale mengukuru jarak sosial yang memisahkan etnis atau kelompok lainnya satu sama lain. Bogardus digunakan di dalam satu kelompok guna menentukan seberapa besar jarak yang dirasakan kelompok tersebut terhadap suatu sasaran atau “luar kelompok.”
Skala ini punya logika yang sederhana. Orang menjawab serangkaian pernyataan yang terurut; pernyataan yang paling dirasa mengancam atau yang jauh jarak sosialnya di satu sisi, dan yang paling tidak mengancam dan dekat jarak sosialnya di sisi lain. Logika skala ini adalah, orang yang menolak kontak atau tidak nyaman dengan item jarak sosial akan menolak item-item yang dekat secara sosial.
Contoh Bogardus sebagai berikut :

Di atas tercantum kuesioner Bogardus yang dibuat tahun 1925 (kiri) dan tahun 1993 (kanan). Perhatikan yang kiri, di mana ada pertanyaan berbunyi “I would willingly admit members of each race”. Atas pernyataan tersebut memilih jawaban antara 1 hingga 7. Mendekati jawaban 1, jarang sosial semakin dekat dan makin mendekati 7 jarak sosial semakin jauh.
Semantic Differential. Semantic Differential menyediakan ukuran tidak langsung pada bagaimana seseorang menyikapi suatu konsep, obyek, atau orang lain. Semantic Differential mengukur perasaan subyektif terhadap sesuatu menggunakan kata sifat. Ini karena orang mengkomunikasikan penilaian mereka lewat kata sifat, baik secara lisan atau tulisan. Karena sebagian besar kata sifat punya perlawanannya (misalnya: gelap/terang, kasar/halus/ lambat/cepat), skala ini menggunakan kata sifat yang berlawanan guna membangun ukuran peringkat atau skala.
Kisaran peringkat Semantif dari 7 hingga 11 poin antara. Berikut kami contohkan skala Semantic Differential:

Dari skala di atas, terdapat 19 pernyataan. Setiap pernyataan diukur dengan 7 skala. Misalnya, antara Good dan Bad terdapat 7 skala. Contoh pernyataan untuk nomor 1 misalnya “Warga DKI Jakarta membuang sampah di tempat yang mudah disapu.”
[Good ___ ___ ___ ___ ___ ___ ___ Bad].
Guttman Scaling. Guttman Scaling juga disebut skala kumulatif, berbeda dengan skala-skala sebelumnya. Ini berarti, peneliti harus mendesain suatu dengan Guttman Scaling dicamkan di dalam benaknya.
Skala Guttman dimulai dengan pengukuran seperangkat indikator atau item. Ini bisa berupan item kuesioner, suara, atau karakteristik yang diamati. Skala Guttman mengukur fenomena berbeda (misalnya pola kejahata, pola menggunakan narkoba, partisipasi politik, gangguan psikologis). Indikator-indikator biasanya diukur dalam jawaban sederhana Ya/Tidak atau Hadir/Absen. Skala Guttman bisa menggunakan 3 hingga 20 indikator.
Peneliti memilih item dengan keyakinan terdapat hubungan logis antar item. Peneliti lalu menempatkan hasilkan ke sebuah skala Guttman dan menentukan apakah item-item tersebut membentuk pola yang seiring dengan hubungan. Contoh skala Guttman kami muat di bawah ini:

Peneliti memilih item dengan keyakinan terdapat hubungan logis antar item. Peneliti lalu menempatkan hasilkan ke sebuah skala Guttman dan menentukan apakah item-item tersebut membentuk pola yang seiring dengan hubungan. Contoh skala Guttman kami muat di bawah ini:

Teknik Pengumpulan Data
Teknik pengumpulan data yang digunakan:
- Kuesioner
- Wawancara
- Content-Analysis
- Focus groups
- Observation
- Video analysis
Teknik Analisis Data
Teknik analisis data berturut-turut adalah Uji Validitas, Uji Reliabilitas, Uji Beda Paired t Sampled Test, dan Importance-Performance Analysis.
1. Uji Validitas Item
Uji Validitas Item atau butir dapat dilakukan dengan menggunakan software SPSS. Untuk proses ini, akan digunakan Uji Korelasi Pearson Product Moment. Dalam uji ini, setiap item akan diuji relasinya dengan skor total variabel yang dimaksud. Dalam hal ini masing-masing item yang ada di dalam variabel X dan Y akan diuji relasinya dengan skor total variabel tersebut.
Agar penelitian ini lebih teliti, sebuah item sebaiknya memiliki korelasi (r) dengan skor total masing-masing variabel ≥ 0,25. Item yang punya r hitung < 0,25 akan disingkirkan akibat mereka tidak melakukan pengukuran secara sama dengan yang dimaksud oleh skor total skala dan lebih jauh lagi, tidak memiliki kontribusi dengan pengukuran seseorang jika bukan malah mengacaukan.
2. Uji Reliabilitas Item
Uji Reliabilitas dilakukan dengan uji Alpha Cronbach. Rumus Alpha Cronbach sebagai berikut:

Note:
- α = Koefisien reliabilitas Alpha Cronbach
- K = Jumlah item pertanyaan yang diuji
- Σs_i^2 = Jumlah varians skor item
- SX^2 = Varians skor-skor tes (seluruh item K)
Jika nilai alpha > 0,7 artinya reliabilitas mencukupi (sufficient reliability) sementara jika alpha > 0,80 ini mensugestikan seluruh item reliabel dan seluruh tes secara konsisten secara internal karena memiliki reliabilitas yang kuat. Atau, ada pula yang memaknakannya sebagai berikut:
- Jika alpha > 0,90 maka reliabilitas sempurna
- Jika alpha antara 0,70 – 0,90 maka reliabilitas tinggi
- Jika alpha antara 0,50 – 0,70 maka reliabilitas moderat
- Jika alpha < 0,50 maka reliabilitas rendah
Jika alpha rendah, kemungkinan satu atau beberapa item tidak reliabel: Segera identifikasi dengan prosedur analisis per item. Item Analysis adalah kelanjutan dari tes Aplha sebelumnya guna melihat item-item tertentu yang tidak reliabel. Lewat ItemAnalysis ini maka satu atau beberapa item yang tidak reliabel dapat dibuang sehingga Alpha dapat lebih tinggi lagi nilainya.
Reliabilitas item diuji dengan melihat Koefisien Alpha dengan melakukan Reliability Analysis dengan SPSS ver. 16.0 for Windows. Akan dilihat nilai Alpha-Cronbach untuk reliabilitas keseluruhan item dalam satu variabel. Agar lebih teliti, dengan menggunakan SPSS, juga akan dilihat kolom Corrected Item Total Correlation. Nilai tiap-tiap item sebaiknya ≥ 0.40 sehingga membuktikan bahwa item tersebut dapat dikatakan punya reliabilitas Konsistensi Internal. Item-item yang punya koefisien korelasi < 0.40 akan dibuang kemudian Uji Reliabilitas item diulang dengan tidak menyertakan item yang tidak reliabel tersebut. Demikian terus dilakukan hingga Koefisien Reliabilitas masing-masing item adalah ≥ 0.40.
Daftar Pustaka
- Andi Field, Discovering Statistics using SPSS, Second Edition (California : SAGE Publication, 2006)
- David D. Vaus, Analyzing Social Science Data: 50 Key Problems in Data Analysis, (Thousand Oaks: Sage Publications, 2002)
- David Wilkinson and Peter Birmingham, Using Research Instruments: A Guide for Researcher (London: RoutledgeFalmer, 2003).
- Donald P. Schwab, Research Methods for Organizational Studies, Second Edition (New Jersey: Lawrence Erlbaum, 2005)
- John A. Martilla and John C. James, “Importance-Performance Analysis” (Journal of Marketing, January, 1977) pp. 77 – 79.
- John W. Lounsbury, Lucy W.Gibson, Richard A. Saudargas, “Scale Development” dalam Frederick T.L. Leong and James T. Austin, The Psychology Research Handbook: A Guide for Graduate Students and Research Assistants(Thousand Oaks: Sage Publications, Inc., 2006)
- Louis Cohen, Lawrence Manion and Keith Morrison, Research Methods in Education, 5th Edition (London: RoutledgeFalmer, 2000)
- Louis Cohen, Lawrence Manion, and Keith Morrison, Research Methods in Education, Sixth Edition (Oxon: Routledge, 2007)
- Marguerite G. Lodico, Dean T. Spaulding, Katherine H. Voegtle, Methods in Educational Research: From Theory to Practice (San Fransisco: John Wiley & Sons, Inc., 2006)
- Pablo E. Subong and McDonald D. Beldia, Statistics for Research (Manila: Rex Book, 2006)
- Perry Roy Hilton and Charlotte Brownlow, SPSS Explained, (East Sussex: Routledge, 2004)
- Rudi Setiawan, “Analisa Tingkat Kepuasan Pengguna Kereta Api Komuter Surabaya – Sidoarjo” (Surabaya: Jurusan Teknik Sipil Universitas Kristen Petra, tt)
- Scott W. VanderStoep and Deirdre J. Johnston, Research Methods for Everyday Life: Blending Qualitative and Quantitative Approaches (San Fransisco: John Wiley & Sons, 2009)
- Sebastian Rainsch, Dynamic Strategic Analysis: Demystifying Simple Success Strategies (Wiesbaden: Deutscher Universitasts-Verlag, 2004)
- W. Lawrence Neuman, Basics of Social Research: Qualitative and Quantitative Approaches, Second Edition (Boston: Pearson Education, .....)
TErima kasih mas Yudi semoga berkah, mengingatkan ilmu yang lama ditinggalkan
ReplyDelete